复杂因子秒级计算,文谛资产的数据库选型方案
来源:互联网 阅读:-
文谛资产首席策略官刘一夫、首席框架官吴永华、首席数据分析师王哲
上海文谛资产管理有限公司(以下简称“文谛资产”)秉持理性、务实、高效、专业的投资精神,凭借科学的量化投资战略、先进的量化交易技术和成熟的风险管理能力深耕量化领域,以创造长期稳定收益为投资目标,为国内外投资者和合作机构提供专业的投资服务。文谛资产业务持续保持稳健发展,公司主要从事CTA和股票的量化策略研究与运作。
大数据技术的飞速发展为量化投资注入了新鲜活力,随着数据挖掘工具的更迭换代,各大投资机构也在不断夯实自身的数据处理和分析能力。文谛资产作为量化统计及应用数学领域的投顾专家,在存储、计算和分析大量时间序列数据的过程中,选择了高性能的分布式时序数据库DolphinDB作为强有力的研究工具。在合作的三年间,DolphinDB为文谛资产提供了集数据库、分布式计算和编程建模于一体的专业服务。本文由文谛资产的首席策略官刘一夫、首席框架官吴永华、首席数据分析师王哲共同撰写,分享关于DolphinDB的使用场景、使用效果、技术服务、选型过程和学习经验。

1.使用场景
我们主要在行情存储、因子挖掘和模型回测三方面用到了DolphinDB。
1.1行情存储
在行情存储方面,我们主要使用DolphinDB进行数据的入库、清洗与查询。
在存储数据时,我们借助DolphinDB的分布式特性,通过提前确定好数据导入的分区字段与分区粒度,提高后续数据检索与分析的效率。比如在查询数据时,DolphinDB会以分区字段为数据过滤,通过SQL引擎快速定位要查找的数据块,从而避免对整张表进行扫描,这极大提高了查询速度。此外,为方便后续的数据分析工作,我们会使用DolphinDB对海量时序数据进行高效清洗,找出并消除残缺、错误或重复的数据,进而输出一份高质量的、满足业务需求的数据。相比其他数据清洗工具随着数据量的增大自身性能会下降的情况,DolphinDB在实际应用中能够保持稳定性能。
1.2因子挖掘
在因子挖掘方面,我们主要使用DolphinDB处理数据量庞大、运算复杂的工作任务。
目前我们处理的总数据量大概在几十TB,每日新增数据约为70GB。在使用过程中,我们不仅会用到DolphinDB高速存取数据的基本功能,同时会用到其内置的多范式编程语言与多种计算引擎。
比如在处理一些tick数据时,我们会使用DolphinDB完成前期的一些运算,然后通过Python API,将计算结果导入Python模型进行组合。其中我们会用到DolphinDB的流计算框架,进行流数据的发布、订阅、预处理、实时内存计算以及复杂指标计算等。以DolphinDB内置的时间序列聚合引擎为例,仅需设定几个参数指标,配合wsum、corr等聚合函数的使用,就可以快速便捷地实现复杂的滑动时间窗口聚合计算。
1.3模型回测
在模型回测方面,我们会用到DolphinDB提供的函数接口、元编程和计算框架,根据这些现有的方法和框架来进行高效回测。
一些现成函数如context by、crossStat等的使用可以帮助我们大大提升数据处理、特别是编程的工作效率。例如context by,该函数作为DolphinDB的独创功能可以实现对时序数据的快速分组。相比group by每组只能返回一个标量值的特性,context by可以使每一个组返回一个和组内元素数量相同的向量。并且在回测工作中,group by只能配合聚合函数使用,但是context by可以与其他聚合函数、移动窗口函数或累计函数等结合使用,这极大方便了研发工作。总的来说,DolphinDB独创的诸多函数功能丰富、使用方便,切实有效地帮助我们提升了回测效率。
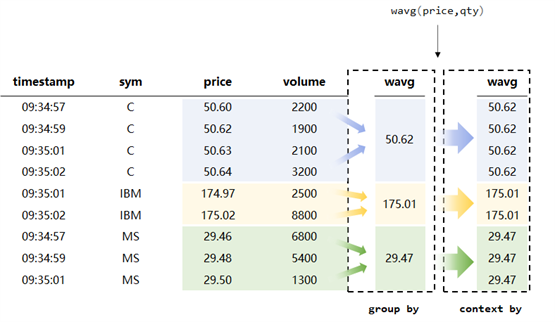
函数示例:DolphinDB context by vs group by
同时,我们会使用DolphinDB的元编程功能。利用元编程设计的程序具有读取、生成、分析及转化其他程序的功能。通过生成动态表达式以及延迟执行的元编程,使得研究人员即便在代码运行时仍可自行修改代码。此外,一些计算框架如MapReduce帮助我们进行并发计算,极大提升了计算效率。
2.使用效果
在行情存储方面,我们的研究人员能够清晰感受到DolphinDB的压缩比率之高和数据落库速度之快。举例来说,在处理几十TB的历史数据时,需要在DolphinDB中压缩数据,而DolphinDB的压缩比例非常优秀,最高可以达到10:1,能够切实地满足我们的业务需求。
在因子挖掘方面,我们经常会计算一些复杂因子。比如使用单日新增数据计算一个复杂因子,可以实现秒级计算。如果使用大量的历史数据,整个测试的运算时间甚至可以控制在分钟级别。
在模型回测方面,由于DolphinDB支持数据项目化的批量处理,因此总体的回测效率很高。比如在进行某个特定参数的测试,整体时间可以控制在1分钟内。再比如对大量历史数据测试全方位的特定参数,从逻辑的实现到最后的产出,整体效率非常高。
3.技术服务
谈及对DolphinDB最深刻的印象,就是技术支持服务。
2020年,我们与DolphinDB CEO周小华博士及技术团队当面进行了深入交流。周博士为我们提供了许多专业的建议,同时技术团队针对我们的业务需求进行了详细记录,并且在后续的跟踪服务中帮助我们逐一实现了需求。
在之后的使用中,我们也会遇到技术疑惑与功能需求。比如今年在处理一些高频数据时,我们急需一些函数的详细用法。在与我们沟通后,DolphinDB的工程师及时教授了我们关于函数的构建、以及改善调优的方法。在平时的技术咨询中,不论是多晚,即便有时是在周末,我们总会得到技术支持工程师们的及时回复。当然,除了技术咨询,我们也会向DolphinDB提出一些开发需求。比如实现因子,虽然有些因子是不常规的、甚至非常复杂,DolphinDB的工程师们都会通过现有的功能向我们提供支持。还有必须提的一点,我们曾经向DolphinDB沟通了一个特别的功能需求,结果这个功能很快就在下一个版本中得到实现。从需求的提出到功能的实现,整体速度确实是非常惊人的。
无论是支持效率,还是专业程度,我们对DolphinDB的技术支持服务都非常满意。
4.时序数据库选型
我们在选型时对比了多家时序数据库,其中主要考虑的是Kdb+与DolphinDB。
Kdb+作为金融领域的老牌时序数据库,虽然名气大、使用面广,但是其作为国外厂商缺乏国内的技术支持,并且其语法晦涩,培训成本和学习成本较高。
DolphinDB在查询和存储方面的性能明显优于其他数据库,其具备的多种流计算引擎对于流数据处理非常友好。同时DolphinDB具有高压缩比,内置丰富的金融函数库,可以极大便捷研发生产。此外,DolphinDB可以提供及时专业的技术支持,同时上手门槛较低。
最终,我们选择了集存储、计算与开发于一体的高性能分布式时序数据库DolphinDB。
5.学习和使用经验
总体来看,DolphinDB的入门是比较容易的。如果有Python和SQL的语法基础,那么只需一两周的时间就可以上手DolphinDB。
若要更加精进地使用DolphinDB,需要对DolphinDB进行更加深入的了解。首先要了解存储引擎的架构,目前DolphinDB使用的是OLAP和TSDB两种引擎,可以提供很高的写入吞吐。其次,要深入理解数据库的设计原理,比如分区表的工作原理,这会大大提升数据查询的效率。然后,在数据计算方面要学习一些高效处理所需的函数,这样在实际业务场景中可以更加自如地使用函数。最后,要保持一颗学习的心态。因为DolphinDB在不断地优化提升,不断地扩展迭代一些新的功能,要用好DolphinDB,一定要保持学习态度、紧跟版本技术动态。
6.结尾
在友好合作的三年间,DolphinDB切实有效地助力文谛资产进行量化投研。希望DolphinDB可以精益求精,未来在行业中的发展越来越好,越来越强。文谛资产也会坚守不断追求创新、大胆向前的精神,推动量化投资向更高更远发展。
推荐阅读:旗龙

相关热点
最新文章
热文榜单
相关推荐



